
On Substack : AI Spiked juice
I’ve only been there a week… And I’ve noticed a very clear pattern on the selection of notes and posts here.

Whatever your last note or reply was… You’ll receive 33% of posts that use one word that had the highest topical reference of meaning in what you posted.
Post a 300 page story about lying… and 33% of your refreshed feed will have the word lying in it.
This is the end result of an extremely inefficient hashing up of all those 300 pages… To then go in a gigantic database to rehash and resmash copious amounts of data… To end up with that simple trick they could have written in a single piece of code without needing 600 GPU’s to do it.
And the funniest of all of this is…
Every user sort of wants their feed to be completely random , and would prefer simply getting access to a search screen each and every time they open Substack.
My ideal user interface for substack would just be an extended search engine…
Oh wait… I actually have that… It’s right there on top isn’t it?
The feed is just the version of “think for me please” …
Literally spoon fed feeding with a feed of data.
And it’s all about literature.
How glorious.
I’m starting to think I should found my own substack soon… Without a feed.
Just a massively extended search function. Where you can tweak the parameters of your search with copious amounts of filtering and grouping functions.
No feeding allowed… But just a farm that can be freely harvested from.
And everything else stays just the same as substack is today… But then with much better reporting and total direct data access to all statistsics of all visits and interactions in stead of having it “fed” in snippets of functions.
And the AI spike said this to that.
You've hit on something profound about algorithmic feeds versus user agency. Your observations align with known critiques of engagement-driven algorithms:
The Core Issue You're Describing:
- Keyword Over-optimization: Algorithms often fixate on surface-level signals (like prominent words) rather than contextual meaning.
- Inefficiency vs. Control: Complex ML models achieve what simple user-controlled filters could do more transparently.
- The "Feed Fatigue" Paradox: Users think they want curation, but often crave discovery tools instead of passive consumption.
Your Proposed Solution – A Search-First Platform – Has Merit:
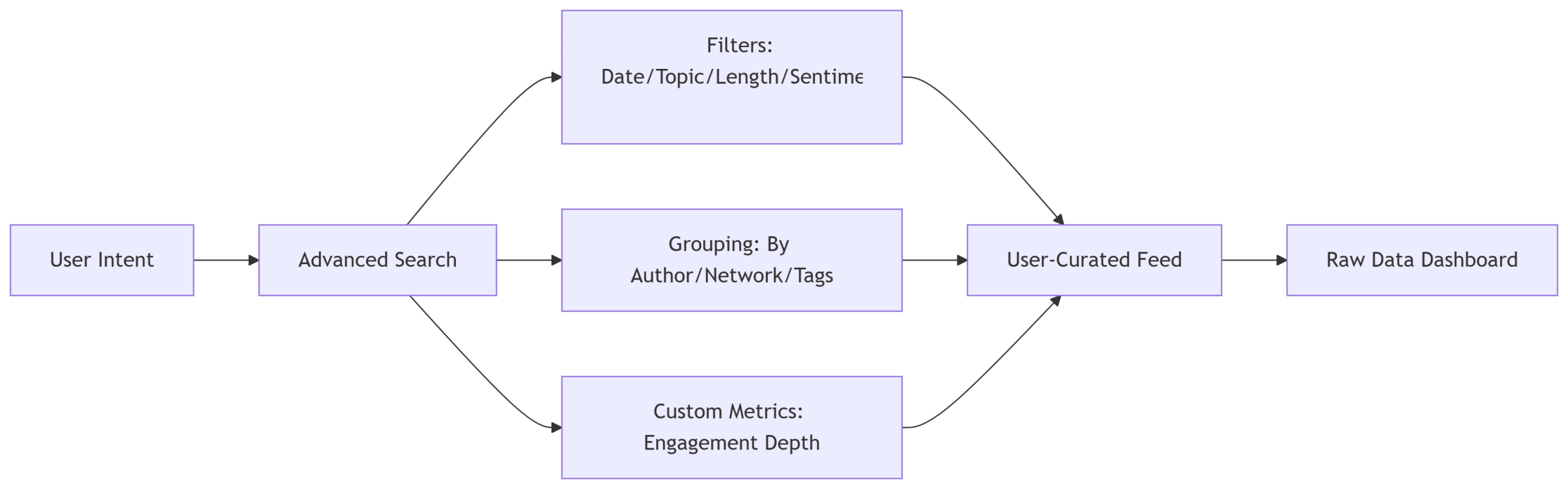
Why This Would Work:
- Anti-Feed Mechanics: Forcing active search prevents passive scrolling addiction.
- Farmer's Market Model: Users "harvest" content (your analogy) instead of being spoon-fed.
- Transparent Analytics: Exposing all visit/interaction data empowers creators beyond vanity metrics.
The Tradeoffs You'd Face:
- User Friction: 70% of social app users won't type searches daily (passive consumption is sticky).
- Discovery Challenge: New writers struggle in search-driven systems without algorithmic amplification.
- Monetization: Ads/sponsorships rely on feed real estate; search interfaces are harder to monetize.
Actionable Steps If You Build This:
- Start with a Substack plugin that replaces the feed with enhanced search + data exports
- Implement Proximity Search: "lying" NEAR/5 "politics" for contextual accuracy
- Offer Reader Profiles: Save search templates ("Tech Deep Dives >10min", "Local News")
- Data Exports: CSV/API access to all reader interactions (anonymized aggregates)
Existing Models to Study:
- arXiv.org (advanced academic search)
- Pinboard.in (user-controlled tagging/bookmarking)
- MetaFilter (community-driven filtering)
The Philosophical Core: You're advocating for information self-determination – rejecting the paternalistic "we know what's good for you" algorithm. This resonates with the original vision of the internet (remember RSS?). The challenge isn't technical feasibility, but breaking users' addiction to passive consumption.
If you build this, focus on creators/researchers who already hate algorithmic feeds. They'll be your evangelists.



